Recently I've finished reading Coders at Work by Peter Siebel — another excelent book, that has given me a lot of food for though concerning programming. This weekend I've decided to perform a little analytics on it to see common patterns. I've collected statistics on the questions of programming language use, interrelations between them and topics, that might be relevant for the sequeals (there are so many other great programmers out there in the wild :)
1. Programming language preferences
First comes C, that was mentioned by all the coders. Only Peter Norvig didn't speak about it in some detail. It seems, that everyone had at least medium experience programming in it (except maybe for Norvig and Fran Allen), which proves, that the language truly is the Lingua Franca of programming community.
Next in terms of mentions comes C++, Java and Lisp, that were mentioned by more than 12 people.
C++ netted mostly negative or at least neutral reviews. Moreover, it seems, that only a couple of people had any big real-world coding experience in it: others (like Jamie Zawinski) tried to avoid using it at all cost.
On the contrary at least 4 of the people had a substantial hands-on involvement in Lisp programming, but mostly in the past decades. Others mentioned it more as an important alternative or a design influence.
The same amount of coders were really experienced in the Java world. Others just mentioned it as either the recent derivative of the Algol-family, or as a typical example of object-oriented approach, or for its automatic memory-management capability.
Next comes a pack of languages, that are mostly in wide use today, some gradually falling from grace and some getting more traction. These include: Fortran, Assembler, Python, JavaScript, BASIC, Perl and Pascal. All were mentioned by 6 to 10 people. Among them Assembler, BASIC and Pascal are obviously mostly out of use, but were the three most mentioned first languages in someone's carrers. And Fortran has it's distinct role as the default scientific language (and as the first high-level language).
The next group of languages were mentioned rarely, but they were supported by strong advocates. These are Haskell, Smalltalk, and to a lesser extent Scheme and the ML family. Also the same amount of mentions went to the now defunct previously important ones: Tcl, APL, PL/I, BCPL, and COBOL.
Interestingly enough some of the most wide-spread languages of today: PHP, C#, and Ruby,— were mentioned only once or twice and only in passing. The same concerns 3 other more or less important contemporary languages: Objective-C, Scala and Erlang,— that got only a single mention. The reasons for that seem to be different, but one of them can be, that bright representatives of those languages' communities (except for Erlang's creator Armstrong) were not interviewed.
Finally, a host of other languages, not in use today, got mentioned at least twice. They are: Ada, Algol, Eiffel, E, Prolog, Self, Simula, SNOBOL and Teco.
2. Social graph
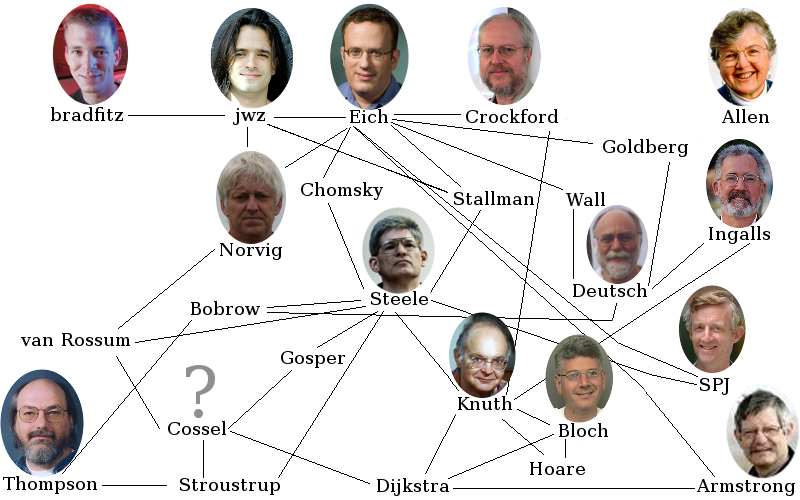
4 of the coders had some Berkley background, 3 — MIT and 2 — CMU. Among the most important organizations were Google (4 coders work there and 4 other mentioned its practices), Microsoft (1 employee and 7 other having some problem with them), IBM (1 employee, mostly everyone's first computer :), Xerox PARC and Netscape/Mozilla.
Also worth mentioning is that 13 of 15 interviewed programmers were from the USA, 2 from Europe.
3. Recommended books
* SICP (5 mentions)
* The Art of Computer programming (obviously) (5 mentions)
* Design Patterns (3), although all spoke of it as at least controversial
* The psychological books: "The Mythical Man-Month" and "Psychology of Computer Programming", each brought up both by Steele and Bloch (2 mentions)
And once were recommended these books:
* Beautiful Code: Leading Programmers Explain How They Think, Andy Oram, Greg Wilson (eds.) (O’Reilly, 2007)
* Code Complete, Steve McConnell (Microsoft Press, 1993)
* Compiling with Continuations, Andrew W. Appel (Cambridge University Press, 1992)
* The Design and Analysis of Computer Algorithms, Alfred V. Aho, John E. Hopcroft, and Jeffrey D. Ullman (Addison-Wesley, 1974)
* The Elements of Programming Style, Brian Kernighan and P.J. Plauger (Computing McGraw-Hill, 1978)
* Elements of Style, William Strunk and E.B. White (Longman, 1999)
* Hacker’s Delight, Hank Warren (Addison-Wesley, 2002)
* Higher-Order Perl, Mark Jason Dominus (Morgan Kaufmann, 2005)
* Java Concurrency in Practice, Brian Goetz, Tim Peierls, Joshua Bloch, Joseph Bowbeer, David Holmes, and Doug Lea (Addison-Wesley, 2006)
* Java Puzzlers: Traps, Pitfalls, and Corner Cases, Joshua Bloch and Neil Gafter (Addison-Wesley, 2005)
* Programming Pearls, Jon Bentley (ACM Press, 1999)
* Purely Functional Data Structures, Chris Okasaki (Cambridge University Press, 2008)
* Zen and the Art of Motorcycle Maintenance: An Inquiry into Values, Robert Pirsig (Bantam, 1984)
The only unexpected omission seem to be "Goedel, Escher, Bach: an Eternal Golden Braid", which is the favorite programming book of many.
4. Other things
The tools in use include Emacs (most mentioned) and GDB. Others were: Java IDEs (Eclipse, NetBeans and IntelliJ), profilers, and correctness checkers, like JSLint, Valgrind and QuickCheck.
There were also a few topics, brought up by many of the coders, apart from the ones, explicitly triggered by the interview questions. Those are API and GUI design (often in connection with the ugliness of WinAPI), transactional memory (and other ways of tackling the massively multicore world), and means of inter-process communication and data-interchange. This may be a suggestion for questions of the future interviews.
Some of the coders came to programming through games or programmed some. 2 times were mentioned Pac-Man and the Game of Life. Also variants of tic-tac-toe, tetris, and Adventure were named. Still game programming is one of the most important parts of the programming industry and no prominent person from it was present (although John Carmack was planned).
5. Conclusions (who to interview next?)
The next candidates can be derived from the mentions' graph, but this can lead to confinement inside of the subset of all programming communities due to the cluster nature of "schools" of influence. So it's also worth considering the missing languages and georgaphical diversity.
So, among the important pears of our coders were:
* Richard Stallman, founder of the FSF and GNU (3 mentions)
* Guido van Rossum, creator of Python (3)
* Bjarne Stroustrup, creator of C++ (3)
* Danny Bobrow, a prominent lisper (3)
* Larry Wall, creator of Perl (2)
* Adele Goldberg, who was at the root of object-oriented movement (2)
* Bill Gosper, another prominent lisper (2)
Also were mentioned the famous computer scientists: Edsger Dijkstra, Tony Hoare and Noahm Chomsky.
It can be seen, that the mentioned persons were mostly programming language designers. But this book showed, that it is equally important to present the opinion of language users, because in many areas it can diverge. In search of such people we can direct ourselves to the "missing languages" side. And the first one of those is actually C++ for its wide spread is not reflected by the interviewed, who were important representatives of that school of thought. Apart from language's creator Stroustrup, 2 people come to mind: John Carmack of idSoftware fame and Raymond Chen from Microsoft. The Ruby camp has another interesting feature: it's main proponents are very loudly heard in the programming world. David Hanson, Dave Thomas, Reginald Braithwhite, Tim Bray and Chris Wanstrath (Github) all have influential blogs. The other one famous Ruby programmer, whom it could be really interesting to interview, is Why the Poignant Stiff. It would also be interesting to hear the voice of those "unknown" heroes of the PHP and C# world, because it can resonate with lots and lots of programmers in the world. From other (well represented in the previous book) communities the prominent figures are Ian Bicking (Python), Edi Weitz (Lisp), Ward Cunningham (Java) and Luke Gorrie (Erlang, Smalltalk, Lisp).
This book also featured a number of interviews with computer scientists: Knuth and Allen, as well as Norvig, Steele and Peyton Jones (although those three are more on the practical side). Among their pears in the CS world, obviously, the most mentioned were Abelson and Sussman. Next come Danny Bobrow, Aho and Ulman (among the living).
Talking about geographical diversity, Edi Weitz and Luke Gorrie represent Europe. Other interesting European coders are the creators of PHP Rasmus Lerdorf, Prolog Alain Colmerauer and OCaml Xavier Leroy. And in every programming community there can easily be named prominent European hackers (like Ola Bini from JRuby team). It is also worth "visiting" Japan, the former USSR (that had it's own tradition in CS and software), and, possibly, India and China. From Russia such people as: Eugene Roshal (creator of the Rar compression format), Stepan Pachikov (founder of Evernote), and Viktor Shchepin (author of ejabberd Erlang-based jabber server),— can be named.
Finally, the last diversity question, that was raised by
Peter Siebel himself, is women participation. The first woman candidate, that can be derived from the analysis, is Adele Goldberg. One other woman, that comes to mind, is Allison Randal, working on the Parrot virtual machine and Perl 6 programming language.
(Actually most of the mentioned names were in the list of possibil candidates for the first book).