Вот видео:
А хотел сказать я всего-то 3 простые вещи, в которых нет ничего особенно нового, но от этого они, как по мне, не теряют своей ценности.
1. Философия Unix для веба
Если говорить о серверной разработке, то самым эффективным подходом к построению масштабируемых систем (как в смысле нагрузки, так и трудоемкости их развития) был и остается Unix way:
small pieces, loosely joined, that do one thing, but do it well
Только в отличие от классики Unix, теперь эти кусочки живут в рамках отдельных узлов сети и взаимодействуют не через pipe, а через сетевые текстовые интерфейсы. Для того, чтобы организовать такое взаимодействие существует ряд простых, надежных, хорошо масштабируемых и, что очень важно, де-факто стандартных и языконезависимых средств. Под разные задачи эти средства разные, и они включают:
- низкоуровневые механизмы взаимодействия: сокеты и ZeroMQ
- высокоуровневые протоколы взаимодействия: HTTP, SMTP, etc.
- форматы сериализации: JSON и еще десяток других
- точки обмена данными: Redis, разные MQs
2. Требования к языкам
Когда программисты сравнивают между собой разные языки, они, как правило, подходят к задаче не с той стороны: от возможностей, а не от требований. Хотя работа в индустрии должна бы была их научить обратному. :) Если же посмотреть на требования, то их можно разделить на несколько групп: требования к языкам для решения неизвестных (исследовательских) задач существенно отличаются от требований к языкам для реализации задач давно отработанных и понятных. Это классическая дихотомия R&D — research vs development — исследования vs инженерия. Большинство задач, с которыми мы сталкиваемся — инженерные, но как раз самые интересные задачи, как с точки зрения профессиональной, так и экономической — исследовательские. Также отдельно я выделяю группу требований для скриптовых языков.
Требования к языкам для исследований
- Интерактивность (минимальное время цикла итерации)
- Поддатливость и гибкость (решать задачу, а не бороться с системой)
- Хорошая поддержка предметной области исследований (если это математика — то хотя бы Numeric Tower, если статистика — то хорошая поддержка матриц, если деревья — то инструменты работы с деревьями и первоклассная рекурсия, и т.д.)
- Возможность решать задачу на языке предметной области (заметьте, что специфические исследовательские языми — всегда DSL'и)
Требования к языкам для решения стандартных задач
- Поддерживаемость (возможность легко передать код от одного разработчика другому)
- Развитая экосистемы инструментов и хорошая поддержка платформы
- Стабильность и предсказуемость (как правило, мало кто любит истекать кровью на bleeding edge, поэтому выбирают то, что работает просто, но без особых проблем, проверенное)
- И, порой самое важное — возможность получить быстроработающий результат (подчас скорость работы отличает решение, которое пойдет в продакшн, от того, которое не пойдет)
Требования к скриптовым языкам
- Первое и основное — хорошая интеграция с хост-системой (оптимизация языка под наиболее часто выполняемые операции в хост-системе)
- Простота и гибкость (я еще не слышал ни об одном статически типизированном скриптовом языке :)
- Минимальный footprint (с одной стороны вся тяжелая работа может делаться на стороне хост-системы, с другой стороны — обычно ресурсы ограниченны и очень мало смысла тратить их на ненужное)
Очень много можно рассуждать о том, какие требования стояли во главе угла при создании тех или иных языков, как языки эволюционируют и т.д. Ограничусь лишь тем, что выделю группу языков, которые однозначно создавались чисто для исследовательской работы — это Matlab, Octave, Mathematica, R, Prolog и разные вариации на тему. Слабость таких языков обычно в том, что в них не были заложены общеинженерные механизмы (прежде всего, первоклассная поддержка взаимодействия с другими системами, которые живут за пределами их "внутреннего" мира).
Один из классических подходов к решению исследовательских задач — двухэтапный метод: разработать прототип системы на исследовательском языке, а затем реализовать полноценную систему уже на инженерном языке, оптимизировав при этом скорость и другие показатели решения, но не меняя его сути. Самым существенным недостатком у него, как по мне, является то, что это может неплохо работать в случае одноразового решения, но если система должна эволюционировать во времени, то все становится существенно сложнее. Ну и, зачем делать дурную работу: хорошо, если язык может поддерживать как исследовательскую, так и инженерную парадигму.
Если предаставить эти требования в виде декартовых координат, и расположить на них языки, и обевсти самую интересная область, в нее попадет совсем немного языков — раз-два и обчелся. Прежде всего, это Lisp, также Python, и, может быть, еще пара-тройка.
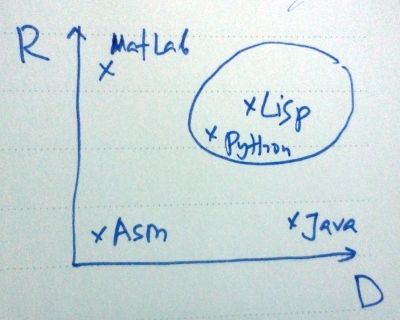
3. Выбор языка под задачу, а не под платформу
Возвращаясь к нашему Unix'у в облаках, отдельные компоненты этой системы могут быть написаны на любом языке (также, как и на обычном Unix'е) и даже работать на любой платформе. Это дает возможность решать специфические задачи тем инструментом, который подходит лучше всего. И среди всего спектра задач преобладают в основном такие, которые, по большому счету все равно, на каком языке делать. Для этих задач обычно самыми главными критериями выбора являются экосистема инструментов и в половине случаев скорость работы результата (во всяком случае в долгосрочном плане).
Но не все задачи такие: есть много разных областей, в которых мейнстримные языки работают плохо или же фактически не работают вообще. Известный афоризм на этот счет — 10е правило Гринспена. Соответственно, если вы хотите использовать Lisp, Haskell или Factor — решайте на них те задачи, на которых они дают очевидное преимущество, и делайте их полноценными гражданами в облачной экосистеме. Так вы на практике, а не в теории сможете доказать их полезность скептикам, и в то же время будут развиваться как знания остальных программистов о них, так и инструментарий этих языков (по которому они часто проигрывают мейнстримным аналогам). Таким образом, в будущем они получат возможность рассматриваться как кандидаты для решения и других задач, для которых их преимущества не столько очевидны (в 2-3 раза, а не на порядок).
P.S. Пару слов о Clojure
В выступлении я много сравнивал Erlang и Clojure. Оба эти языка делают упор на конкурентную парадигму разработки. Но Erlang в этом смысле стоит особняком от других функциональных языков, поскольку конкурирует с императивными языками не столько на уровне качества языка для решения конкретных задач, сколько как язык-платформа, создающий новую парадигму решения задач за рамками отдельного процесса и отдельной машины. Таким образом, его главная ценность — это роль системного языка для распределенных систем.
Что касается Clojure, то я в шутку разделил все языки на фундаментальные и хипстерские. Фундаментальные языки (такие как C, Lisp, Erlang, Haskell, Smalltalk) появляются, когда группы умных людей долго работают над сложными проблемами и в процессе создают не просто язык, а целую парадигму. В то же время хипстерские языки являются продуктом обычно одного человека, который хочет здесь и сейчас получить самое лучшее из нескольких языков сразу, гибрид. Я перечислял такие примеры, как C++ (C + классы + еще куча всего, понадерганного с разных сторон) — это, пожалуй, архетипный хипстерский язык,— Ruby (Perl + Smalltalk + Lisp), JavaScript (C + Scheme), который со времени пояления V8 и node.js перешел из категории скриптовых языков в общесистемные. Кстати, в большинстве случаев языки второго типа более успешны в краткосрочном плане и завоевывают мир. Точнее, их мировое господство чередуется с господством языков, которые стоят в этом спектре где-то посередине: когда люди устают от подобных гибридов, их в конце концов "побеждают" более здравые варианты. Java вместо C++, Python вместо Ruby (для веба), посмотрим, что будет вместо JS. К сожалению, Clojure — яркий пример такого гибрида: это попытка скрестить Lisp с Haskell'ем, да еще и на Java-основе...


No comments:
Post a Comment