OK, let's get started with the NLTK book. Its first chapter tries to impress the reader with how simple it is to accomplish some neat things with texts using it. Actually, the underlying algorithms that allow to achieve these results are mostly quite basic. We'll discuss them in this post and the code for the first part of the chapter can be found in nltk/ch1-1.lisp.
Setting up texts for processing
For the purpose of this demonstration we'll need several texts which can be downloaded from NLTK data. Namely, we'll use the following 5 texts:
- Moby Dick (can be found inside Project Gutenberg)
- Sense and Sensibility (likewise from Project Gutenberg)
- The Book of Genesis
- Inaugural Address Corpus (this one comes as a collection of separate texts, that you'll need to cat together into one file)
- NPS Chat Corpus
These texts are in nltk/data/ directory in CL-NLP.
NLTK guys have created a special Text class and have defined all the operations in this chapter as its methods. We'll employ a slightly simpler approach and implement them as ordinary functions. Yet we'll also have a special-purpose text class to cache reusable results of long-running operations, like tokenization.
NLTK> (load-nltk-texts "data/")
#<MOBY [Moby Dick by Herman... 1242986>
#<SENSE [Sense and Sensibili... 673019>
#<GENESIS In the beginning God... 188665>
...As you've already guessed, we've just loaded all the texts. The number in the last column is each text's character count.
Now they are stored in *texts* hash-table. This is how we can access an individual text and name it for future usage:
(defparameter *sense* (get# :sense *texts*))get# is one of the shorthand functions for operating on hash-tables defined in rutils.
Now we have a variable pointing to "Sense and Sensibility". If we examine it, this is what we'll see:
NLTK> (describe *sense*)
#<SENSE [Sense and Sensibili... 673019>
[standard-object]
Slots with :INSTANCE allocation:
NAME = :SENSE
RAW = "[Sense and Sensibility by Jane Austen 1811]..
WORDS = #<unbound slot>
CTXS = #<unbound slot>
TRANSITIONS = #<unbound slot>
DISPERSION = #<unbound slot>As you see, there are some unbound slots in this structure: words will hold every word in the text after tokenization, ctxs will be a table of contexts for each word with their probabilities. By analogy, transitons will be a table of transition probabilities between words. Finally, dispersion will be a table of indices of word occurrences in text. We'll use a lazy initialization strategy for them by defining slot-unbound CLOS methods, that will be called on first access to each slot. For example, here's how words is initialized:
(defmethod slot-unbound (class (obj text) (slot (eql 'words)))
(with-slots (raw words) obj
(format t "~&Tokenizing text...~%")
(prog1 (setf words (mapcan #`(cons "¶" (tokenize %))
(tokenize raw)))
(format t "Number of words: ~A~%" (length words))))) First we split the raw text in paragraphs, because we'd like to preserve paragraph information. Splitting is slightly involved as paragraphs are separated by double newlines, while single newlines end every line in the text, and we have to distinguish this. We insert pillcrow signs paragraph boundaries. Then we tokenize the paragraphs into separate words (real words, punctuation marks, symbols, etc).
NB. I consider tokenization the crucial function of the NLP toolkit, and we'll explore it in more detail in one of the future posts.
Implementing the examples
OK, now we are ready to start churning out examples from the first chapter.
The first one finds occurrences of certain words in the text. NLTK guys perform the search on the tokenized texts. But I think, it's quite OK to do it on raw strings with regexes. This has an added benefit of preserving text structure.
NLTK> (concordance *moby* "monstrous")
Displaying 11 of 11 matches
former, one was of a most monstrous size. ... This came towards
"Touching that monstrous bulk of the whale or ork we h
array of monstrous clubs and spears. Some were
you gazed, and wondered what monstrous
has survived the flood; most monstrous
monstrous fable, or still worse and mor
Of the Monstrous Pictures of Whales.
In connexion with the monstrous pictures of whales, I am stro
o enter upon those still more monstrous stories of them
ave been rummaged out of this monstrous
Whale-Bones; for Whales of a monstrous size are With :pass-newlines on we can get the output similar to NLTK's. Let's try one of the homework tasks:
NLTK> (concordance *genesis* "lived" :pass-newlines t)
Displaying 75 of 75 matches
t from Yahweh's presence, and lived in the land of Nod, east of
when they were created. Adam lived one hundred thirty years, and
...Now let's try similarity. Here we won't do without proper tokenization.
NLTK> (similar *moby* "monstrous")
Building word contexts...
Tokenizing text...
Number of words: 267803
Number of unique words: 19243
("mystifying" "subtly" "maddens" "impalpable" "modifies" "vexatious" "candid"
"exasperate" "doleful" "delightfully" "trustworthy" "domineering" "abundant"
"puzzled" "untoward" "contemptible" "gamesome" "reliable" "mouldy"
"determined")NLTK> (similar *sense* "monstrous")
Building word contexts...
Tokenizing text...
Number of words: 146926
Number of unique words: 6783
("amazingly" "vast" "heartily" "extremely" "remarkably" "great" "exceedingly"
"sweet" "very" "so" "good" "a" "as")We mostly get the same words as NLTK's result, but with a slightly different ordering. It turns out, that the reason for this is very simple. The function similar matches words based on the contexts, where they occur. According to the famous quote by John Rupert Firth:
You shall know a word by the company it keeps
But if we look at context overlap between various words from our list we'll see that the similarity relation between all these words is extremely weak: the decision is based on the match of a single context in which both words appeared in text. In fact, all the listed words are similar to the same extent.
NLTK> (common-contexts *moby* "monstrous" "loving")
("most_and")
NLTK> (common-contexts *moby* "monstrous" "mystifying")
("most_and")
NLTK> (apply #'common-contexts *moby* (similar *moby* "monstrous"))
("most_and")Actually, the next NLTK example is, probably, the best context overlap you can get from those texts:
NLTK> (common-contexts *sense* "monstrous" "very")
("am_glad" "is_pretty" "a_pretty" "a_lucky")Now let's draw a dispersion plot of the words from inaugural corpus. This task may seem difficult to approach at first, because the authors use a Python library matplotlib for drawing the graph. Fortunately, there's a language-agnostic tool to achieve similar goals, which is called gnuplot. There is a couple of Lisp wrapper libraries for it, and the actual code you need to write to drive it amounts to 2 lines (not counting the code to format the data for consumption). There are, actually, numerous language-agnostic tools on the Unix platform — don't forget to look for them when you have such kind of specific need :)
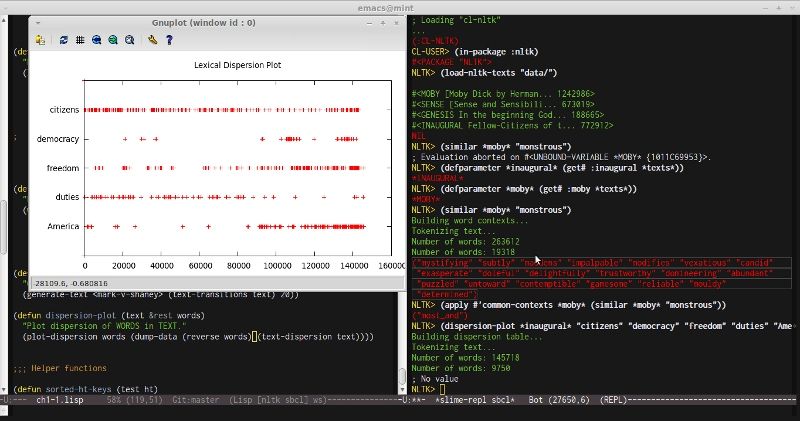
The next problem in this part also seems pretty hard. And, in fact, it is extremely hard if framed correctly — to generate a meaningful text based on some other text. But the example solves an easier task to generate a somewhat meaningful text. And the approach taken to solve it is a very simple one — it is the baseline method in this area and is based on Markov chains. There was even a famous mock with Markov chains in the times of Usenet called Mark V. Shaney. Markov models have one principal parameter — order. Mark V. Shaney was an order 2 chain.
Let's try to generate something with it:
NLTK> (princ (generate *genesis* :order 2 :n 93))
Building prefix transitions index of length 2...
Number of prefixes: 14326
In the marsh grass . Behold , the male and female . Of these , and that Jacob obeyed his father . I will return to the earth was dry . God set them in the earth . Noah built an altar there , and put me in the pit ; and that which was our father ' s hand , then the handmaids and their sin is very grievous in your flesh for an everlasting covenant between God and every man to see the nakedness of his flock and keep it .And what if we raise the order?
NLTK> (princ (generate *genesis* :order 3 :n 93))
Building prefix transitions index of length 3...
Number of prefixes: 28206
In the beginning God created the large sea creatures , and every bird , whatever moves on the earth . He stayed yet another seven days , and sent over that which he had gained in Paddan Aram . Esau saw that the interpretation was good , he said to them , they conspired against him to kill him . They took captive all their little ones , and for days and years ; and let it divide the waters from the waters . God said to the younger , and his seed
The text starts to resemble the original more and more. Also you may notice, that the text will always start with "In". That's because Genesis isn't split in paragraphs, and our generation starts from paragraph beginnings, of which there's only one here.
OK, this seems to work, but with probabilities you never know for sure... ;)
Now, we're left with very simple tasks. Let's just do them:
NLTK> (length (text-words *genesis*))
44671In the book they had a slightly different number: 44764. This is because of the different tokenization scheme. The differences can be seen in the next snippet (we have a cleaner version for this use case :)
NLTK> (take 20 (sort (remove-duplicates (text-words *genesis*) :test 'string=) 'string<))
("!" "\"" "'" "(" ")" "," "-" "." ":" ";" "?" "A" "Abel" "Abida" "Abimael"
"Abimelech" "About" "Abraham" "Abram" "Accad")What about the vocabulary size? Well, once again very similar to the NLTK number (2789).
NLTK> (length (remove-duplicates (text-words *genesis*) :test 'string=))
2634Now, let's look for words:
NLTK> (count "smote" (text-words *genesis*) :test 'string=)
0Hmm... What about some other word?
NLTK> (count "Abraham" (text-words *genesis*) :test 'string=)
134This seems to work. What's the problem with "smote"? Turns out, there's no such word in the Genesis text: at least the examination of the text doesn't show any traces of it. Looks like we've found a bug in the book :)
(defun percentage (count total)
(/ (* 100.0 count) total))
NLTK> (with-slots (words) *inaugural*
(percentage (count "a" words :test 'string=) (length words)))
1.4597242(defun lexical-diversity (text)
(with-slots (words) text
(/ (float (length words))
(length (remove-duplicates words :test 'string=)))))
NLTK> (lexical-diversity *genesis*)
16.959377
NLTK> (lexical-diversity *chat*)
6.9837084Interestingly, the results for *chat* corpus differ from the NLTK ones, although they are calculated based on tokens, provided in the corpus and not extracted by our tokenization algorithms. This text is special, because it is extracted from the XML-structured document, which also contains the full tokenization. To use it we swap words in *chat* corpus:
NLTK> (setf (text-words *chat*)
(mapcar #'token-word
(flatten (corpus-text-tokens ncorp:+nps-chat-corpus+))))But first we need to get the corpus and extract the data from it - see corpora/nps-chat.lisp for details.
And, finally, we can examine the Brown Corpus.
Genre | Tokens | Types | Lexical Diversity
--------------------+----------+---------+--------------------
PRESS-REPORTAGE | 100554 | 14393 | 7.0
PRESS-EDITORIAL | 61604 | 9889 | 6.2
PRESS-REVIEWS | 40704 | 8625 | 4.7
RELIGION | 39399 | 6372 | 6.2
SKILL-AND-HOBBIES | 82345 | 11934 | 6.9
POPULAR-LORE | 110299 | 14502 | 7.6
BELLES-LETTRES | 173096 | 18420 | 9.4
MISCELLANEOUS-GOVER | 70117 | 8180 | 8.6
LEARNED | 181888 | 16858 | 10.8
FICTION-GENERAL | 68488 | 9301 | 7.4
FICTION-MYSTERY | 57169 | 6981 | 8.2
FICTION-SCIENCE | 14470 | 3232 | 4.5
FICTION-ADVENTURE | 69342 | 8873 | 7.8
FICTION-ROMANCE | 70022 | 8451 | 8.3
HUMOR | 21695 | 5016 | 4.3
OK, seems like we're done with this chapter. So far there was no rocket science involved, but it was interesting...
Implementation details
So, what are the interesting bits we haven't discussed?
First, let's look at a small optimization trick for calculating lexical-diversity. Our initial variant uses a library function remove-duplicates which is highly inefficient for this case.
NLTK> (time (lexical-diversity *chat*))
Evaluation took:
9.898 seconds of real time
9.888618 seconds of total run time (9.888618 user, 0.000000 system)
99.91% CPU
23,687,560,947 processor cycles
229,392 bytes consedWhat we'd like to do is something similar to the Python's version, which puts everything in a set and calculates its size. A set is easily represented with a hash-table:
(defun uniq (list &key raw case-insensitive)
"Return only unique elements from LIST either as a new list
or as hash-table if RAW is set. Can be CASE-INSENSITIVE."
(let ((uniqs (make-hash-table :test (if case-insensitive 'equalp 'equal))))
(dolist (elt list)
(set# elt uniqs t))
(if raw uniqs (ht-keys uniqs))))Here's the time of the same calculation using uniq:
NLTK> (time (lexical-diversity *chat*))
Evaluation took:
0.014 seconds of real time
0.012001 seconds of total run time (0.012001 user, 0.000000 system)
85.71% CPU
33,396,336 processor cycles
613,568 bytes consedA 1000x speed increase!
Now, let's return to text generation. It is accomplished with the following loop (a simplified version):
(loop :for i :from 1 :to length :do
(let ((r (random 1.0))
(total 0))
(dotable (word prob
(or (get# prefix transitions)
;; no continuation - start anew
(prog1 (get# (setf prefix initial-prefix) transitions)
;; add period unless one is already there
(unless (every #'period-char-p (car rez))
(push "." rez)
(incf i)))))
(when (> (incf total prob) r)
(push word rez)
(setf prefix (cons word (butlast prefix)))
(return)))))On each iteration it places all possible continuations of the current prefix on a segment from 0 to 1 and generates a random number that points to one of the variants. If there's no continuation it starts anew.
NLTK book, actually, uses a slightly more complicated model: first, it builds a probability distribution on top of the transition frequencies and then generated the text from the probabilities. As of now I don't see why this is needed and if it makes any difference in the results.
And, finally, here's how we draw the dispersion plot:
(defun plot-dispersion (words file)
"Plot WORDS dispersion data from FILE."
(cgn:start-gnuplot)
(cgn:format-gnuplot "set title \"Lexical Dispersion Plot\"")
(cgn:format-gnuplot "plot \"~A\" using 1:2:yticlabels(3) title \"\"" file))It's just 1 line of gnuplot code, actually, but we also need to prepare the data in a tab-separated text file:
(defun dump-data (words dispersion-table)
"Dump data from DISPERSION-TABLE for WORDS into a temporary file
and return its name."
(let ((filename (fmt "/tmp/~A" (gensym))))
(with-out-file (out filename)
(format out "0~t0~t~%")
(doindex (i word words)
(dolist (idx (get# word dispersion-table))
(format out "~A~t~A~t~A~%" idx (1+ i) word)))
(format out "0~t~A~t~%" (1+ (length words))))
filename))To wrap up, we've seen a demonstration of a lot of useful tools for text processing, and also discussed how they can be built. Among all of them I want to outline the utility of a seemingly simplistic concordance that is actually kind of a grep tool that is indispensable for large text exploration. I even used it a couple of times debugging issues in more complex functions from this pack.
- Previous: Introduction
No comments:
Post a Comment